Мы уже видели, что отчуждаемое (и визуализируемое) знание не сводится к только императивному; существует ещё по крайней мере декларативное. Как показано при классификации содержания отчуждаемых знаний в этом подпункте, и это ещё не всё; поэтому нужны комплексные языковые средства. Рассмотрим, как их можно построить.
Содержание
Структуры данных в алгоритмических процессах
Вначале - некоторые общие соображения, как целостно и системно визуализировать (на основе графов) содержание программы.
Идея техноязыка – визуализировать алгоритмы, сделав схемное представление основным, а текстовое и/или табличное – дополняющим, как показано в классификации из п/п 1.4.2.1. А как сделать то же самое для структур данных? Попробуем предложить некоторые возможности.
Прежде всего нужно показать структуру неатомарных типов; это возможно, если атомарные обозначить некими иконами и сделать их вершинами схем более сложных типов. Очевидным образом сложные базовые типы можно показать как деревья. Произвольные типы будут изображаться другими конечно-графовыми структурами – как иерархичными, так и неиерархичными. При этом можно повторное вхождение типа обозначить циклом, а выбор между типами для включения в подструктуру (возможный в некоторых прогязыках) – ветвлением, заимствовав их графику из того же техноязыка.
Далее следует как-то показать вхождение величин в алгоритм (систему алгоритмов). Для этого можно ввести орграф-схему модульной структуры, вершинами которой будут алгоритмы (основные и вспомогательные), а рёбрами – отношения вхождения одних алгоритмов в другие. При этом текст вершины представляет собой объявления величин в данном алгоритме, а текст (метка) ребра – указания видимости величин, объявленных в начальном алгоритме, для конечного алгоритма. Это будет визуализацией механизма экспорта/импорта величин, описанного ранее для прогязыка Оберон-2.
По сути, это не декларативная схема, а разновидность схемы модуляризации (обобщённой структуризации) решения задачи. Такую схему можно «нагрузить» дополнительными данными и в итоге прийти к широкофункциональному языку структуризации типа MIL-751.
Отметим, что можно исходить из противоположного принципа графовой интерпретации – считать алгоритмы рёбрами, а указания экспорта/импорта – вершинами; но о смысле этого следует ещё подумать.
Наконец, следует изобразить объявления конкретных величин, определённых через встроенные и сочинённые для данной задачи типы данных.
Возникает вопрос: не пытаемся ли мы «скрестить ужа с ежом», т.е. определить универсальный язык для объектов всех предметных областей сразу? Дело в том, что мы решаем несколько иную задачу – не об общем языке, а о единообразной информатизации всех деклар-языков, т.е. сведению их к конечным структурам данных. В самом деле, и схемы, и карты, и тексты состоят в конечном счёте из геометрических фигур, обладающих некими различимыми перципиентом физическими свойствами, которые используются как информативные признаки. Сами же элементы данных состоят в конкретных логических отношениях, отражающих реальные зависимости между представляемыми реальными объектами; и эти зависимости тоже можно (и нужно) описать единообразно. Наконец, элементы и отношения как-то кодируются для целей построения структур данных.
По сути, здесь изложены основания концепции т.н. «трёх схем», хорошо известной специалистам-датаматикам (напр. проектировщикам и администраторам АБнД).
Можно ли распространить эту концепцию на алгоритмику? Видимо, да; здесь т. зр. человека будут представлять прежде всего различные сценарии взаимодействия с системой (различно формализованные – хотя бы в такой форме, как «процесс эксплуатации бетономешалки с программным управлением» в известной истории М. Задорнова про агента Джона Кайфа :)); машинную – программный код, а шире – любая овеществлённая система законов управления (выраженная, допустим, в расстановке шпеньков определённых размеров и форм на кодовом валике «музыкальной шкатулки» или в профилях кулачков распредвала). Нейтральную же т. зр. отражает как раз алгоритмическое описание деятельности – напр., на том же техноязыке.
Если смотреть шире, то Паронджанов предложил концепцию схематизации – эргономизированного представления предметных областей с предварительной структуризацией содержания и последующей визуализацией структуры в виде схем (графов, диаграмм). На основе этого подхода разработаны такие визуальные языки, как:
ГРАФ – создан Г.А. Гуленковым как язык обобщённой (начальной) визуализации структурированного содержания;
ГНОМ – компактный язык для упрощённой схематизации.
Очевидно, нужны усилия по выработке единого стандарта представления деклар-знаний как системы языков, охватывающих разные уровни формализации вплоть до программного. Модели на языках этого семейства также д.б. единственными источниками знания об объектах деятельности, начиная с информатического моделирования или раньше.
Исходя из уточнённой классификации знаний, нужен по крайней мере один язык описания структуры объектов (графический) и язык атрибуции объектов (элементов).
На сегодня предлагается:
декларировать объекты в иконах Полка, предшествующих любым другим операторам визуала; там же задавать их свойства (используемые в выражениях);
нестрого типизировать объекты визуала-эскиза, особенно физические;
использовать один из двух статусов видимости переменных величин: глобальный или локальный, указывая его при декларировании величины перед типом; во вставках допускать принудительную глобализацию/локализацию переменных.
указывать свойство объекта перед его именем через точку, если нужно использовать это свойство в выражении (как величину); для использования набора свойств можно поступить по-разному, но строгости ради повторяем полную запись «СвойствоОбъекта.ИмяОбъекта» при каждом употреблении.
Также вводится семейство деклар-языков (см. Приложение 2); однако эти языки в текущем виде можно считать лишь качественными, и для дальнейшей формализации нужно определять более формальные.
Помимо прочего, не стоит злоупотреблять сокращениями; как справедливо указывается в /4, с.189/ «...человек, читающий произведение, должен тратить усилие на декодирование. Традиция сокращений происходит с того времени, когда бумага стоила дорого, а человеческое время – дёшево.»
Читая данный документ, Вы, конечно, обратили внимание, что здесь всё-таки употребляются глубокие сокращения, но лишь типовые, для вспомогательных слов и сочетаний; в остальных случаях употребляются сложносокращённые слова, сохраняющие смысл. Также используются аббревиатуры, но лишь при условии, когда это: позволяет избавиться от «хвоста» в абзаце, где мы этого очень хотим; делает более обозримым сложное предложение, которое нам неохота разбивать на более простые:–) Кроме того, сокращения дают определённую экономию времени человека в случаях удалённого доступа к документу в предметной форме; чем короче текст, тем быстрее его можно загрузить.
В тексте икон можно употреблять сокращения в тех же случаях, только на объём предметной формы это практически не влияет из-за графического представления; при поиске также требуется распознавание знаков (что справедливо и для других визуальных моделей).
Возвращаясь к деклар-знанию, определим графит-язык абстрактных типов (АТ) алгоритмических величин. В связи с этим наметим подход к визуальному представлению деклар-знания – т.е. сущностной структуры описываемой задачи, предметной области – в информатизованном виде.
Прежде всего это представление следует из метаструктуры знания, которое нужно отображать. А она подразделяется на две составляющих - сущности как ограниченные по использованию местом в описании объекты (имеющие конечную область "видимости", что вытекает из информатической строгости описания), т.е. "страдательные" в этом смысле и сущности-прародители областей видимости, т.е. "действительные" в этом смысле. Одни от других надо как-то зрительно отграничивать для удобства "разбора" модели. Далее, ограничения использования образуют иерархию - и её тоже надо как-то зрительно обозначать.
Что же взято за основу? Прежде всего обычные стереотипы организации восприятия, обусловленные в основе физикой. Во-первых, это "принцип горизонта" - одноранговые сущности упорядочиваются по горизонтали, а ранги - по вертикали (как реальные небо и земля). Во-вторых "вертикальность симметрии/асимметрии" - оси деления объёмов чего-либо привычнее проводить по вертикали (как идёт вектор силы тяжести). Поэтому всё, что попадает в область видимости данного уровня, мы располагаем "в строку". А ось деления объектов в этой строке на "действительные" и "страдательные" мы проводим по вертикали (ею служит выход вершины-прародителя).
Ещё одно отличие в логике структур. Обычно "дерево объектов" организуется как "дерево каталогов" в ГИП-оболочках ОС. Однако это логика приципиальных схем - маршруты идут как сигнальные тракты слева направо, а сигналы разного смысла различаются только по подписям - в схемах же каталогов вообще предполагается одно значение "сигналов" - "это входит в то". Нам же нужно показать логику отношений сущностей к областям видимости. Отношение удобно показывать как узел "один ко многим" - что и введено как ОС-описатели - а тип отношения показывается графикой узла-описателя (см. п/п 1.3.1.4 в этом пункте). Причём отношения не только однородные - на абстрактных схемах (учебно-исследовательского назначения).
Принцип "связи - это горизонтальные/вертикальные отрезки" предопределяет линейчатую форму ОС-узлов.
В принципе и "дерево каталогов" можно было бы организовать для отображения указанных свойств - но читабельность "поперёк горизонта", пожалуй, ухудшится.
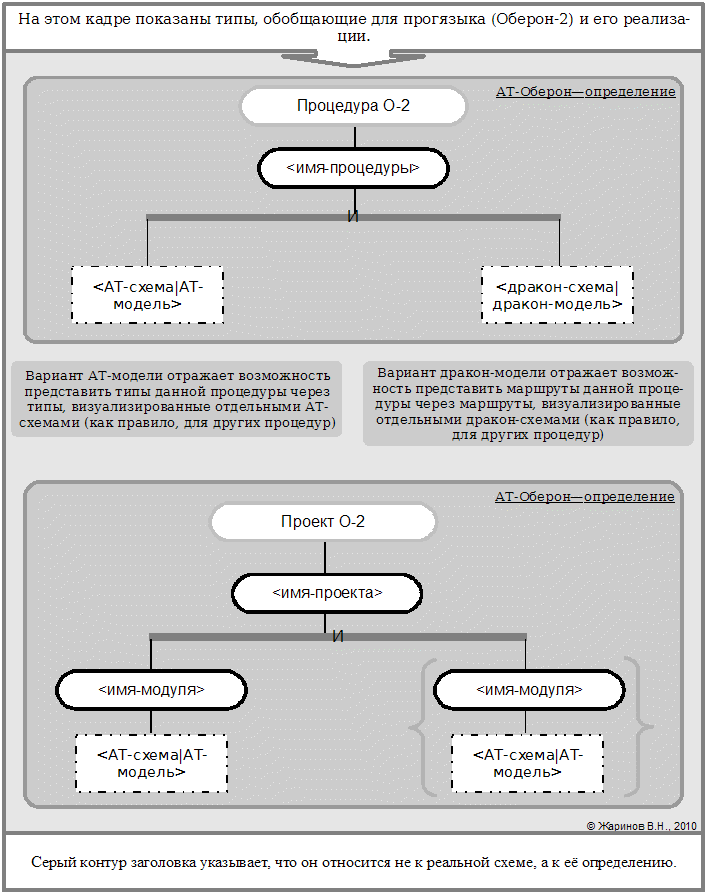
Пример неоднородных отношений - определения неатомарных типов абстрактными АТ-схемами. Два таких определения даны далее.
Возможность расширения записи означает использование абстрактного определения типа запись в самом этом определении, т.е. рекурсию, что на схеме АТ-определения показано зацикливанием.
Вышесказанное и определяет организацию АТ-схемы как "дерева коромысел".
В конкретной (практической) АТ-схеме тоже возможны циклы - если имеется рекурсия. Однако это относится только к прямой (вложению вызова процедуры в её же текст); косвенная рекурсия (вызов данной процедуры из другой, которая ранее вызывается из данной, возможно, через ряд промежуточных вызовов) не показывается текстуальным вложением столь же прямо. Но на АТ-схеме это можно отразить— показав линейный порядок, приводящий к рекурсии, как ветвь, нагруженную цепочкой процедурных вершин по порядку вызова, где последняя отображает рекурсивный вызов; далее маршрут зацикливается на заголовок.
При сложной рекурсивной организации такие изображения могут загромождать АТ-модель; впрочем, в практике такие «навороты», видимо, не столь часты.
Для единообразного показа порядка исполнения процедур служит ДМ-схема. Вхождение же процедур через подстановку в АТ-схеме также можно показать дополнительной веткой, нагруженной процедурными вершинами в порядке следования в тексте.
В качестве вершин в этом случае, как и в импер-модели, можно использовать виопы Вставка; они будут показывать, что вложенность процедур не текстуальная и отсылать по имени к их АТ-(а равно и к дракон-) определениям.
Маршруты вызова можно выделить оформлением — напр., изменением цвета линий, стиля; также имеет смысл в редакторе АТ-схем реализовать отключение/включение их показа.
Другое дело, что сведения получаются разрозненными. Ведь мы фактически показываем при сочинении, что может происходить во время исполнения программы (in-runtime), когда набор процедур организуется в порядок вызова сообразно значениям исходных и промежуточных данных задачи. А может и не происходить — ведь маршрут, приводящий к рекурсии, не обязательно будет выбран, если тела процедур нелинейны.
Не менее сложно визуализировать и указательные типы — потому что здесь также имеем динамику использования (runtime-аспект). Целесообразно показать указатель как «разъёмное соединение» с указуемой сущностью; при этом «ответная часть разъёма» может символизировать процедуру размещения сущности в памяти исполнителя.
Каждый ОС-узел обозначает границы области видимости. При этом надо иметь в виду, что по правилам структурно-модульного программирования область модуля, и только она, глобальна — т.е. находящиеся в ней величины видны изо всех процедур, вложенных в модуль.
Применительно к граф-представлению это значит, что все «страдательные» ветки, привешенные к верхнему «коромыслу», надо мысленно привешивать также к каждому из остальных.
Практически это значит, что процедура может читать и/или записывать значение величины.
Из этого правила есть исключение — когда в процедуре (локально) определена величина, одноимённая глобальной и того же типа, то локальная величина перекрывает глобальную, т.е. видна вместо глобальной внутри (и только внутри) данной процедуры.
Соответственно мы должны либо учитывать перекрытия, либо на деклар-графе как-то явно показывать их. Можно показывать явно и глобальные величины (в РДП-редакторе — автоматически), исключая перекрытые, но это усложнит схему.
Если оформить ветки дублей глобальных величин менее контрастно, чем ветки локальных, то усложнение, возможно, окажется разумным.
Заметим, что ограничение области видимости имеется в виду текстуальное - как процедуры вложены друг в друга. В примерах это не оговаривается, но в определении АТ-языка, конечно, должно быть. Для вызовов же процедур вложение показывается ДМ-схемами.
Правые ветви поддерева процедуры определяют текстуально входящие деклар-сущности. Предлагаются следующие принципы организации этих ветвей:
Одна ветвь определяет только сущности одного типа; тем самым каждая ветвь нагружается только определёнными вершинами АТ-алфавита. Однородные по типу сущности объявляются в одной вершине перечислением их имён.
Типы делятся на категории по секциям последовательности определений, выделяемым стандартом прогязыка (типы, переменные, константы, процедуры). Секция замыкается вершиной-терминалом, текст которой указывает род секции.
Ветвей для однотипных сущностей м.б. более одной (обычно это нужно для удобства компоновки АТ-схемы); каждый составной тип определяется в своей ветви.
Объявления типов (неатомарных и именованных) используются для определения как типизированных величин, так и новых типов (производных, в т.ч. от неатомарных). Это визуализируется заголовками объявлений и операторами определения новых типов. В АТ-языке принято показывать объявление нового типа: приравниванием (в вершине Полка типа), если производный тип полагается равным базовому, но разноимённым; подстановкой (в вершине Вставка типа), если производный тип использует определение базового как составную часть (наряду хотя бы с ещё одним атомарным/неатомарным типом).
Использование сущностей, импортированных из других модулей, обозначать как обычно, с уточнением имени, группируя в отдельные ветки по секциям; в имя секции включать 'Imp'. При этом импортируемые процедуры также располагать в глобальной области, т.к. они видимы во всём модуле, как ветки секции (вариант — в одной ветке цепочкой, но это нарушает общий принцип и м.б. не так понятно).
Эти принципы реализуются в системе правил АТ-языка.
Область видимости именована в заголовке поддерева (АТ-схемы или процедуры). ОС-узел играет ещё одну синтаксическую роль — отделяет видимое от сокрытого областью. Поэтому содержимое входного шампура видимо в вышележащей области, что используется далее.
Имеется также вопрос с отображением других элементов заголовочного синтаксиса, помимо имени процедуры. Как видно, связь с типом предлагается указывать в тексте процедурной вершины; туда пишется непосредственно имя приёмника сообщений. Так же можно поступить с типом процедуры-функции.
Такой подход не вводит лишних вершин, которые могут не облегчить, а затруднить чтение; указанные элементы присутствуют в единственных экземплярах, и достаточно отделить их в строки, чтобы удобно читать в тексте одной — процедурной - вершины.
С формальными параметрами ситуация сложнее; их число переменно, описание сложно (особенно в КП-диалекте Оберона, где вводятся модификаторы-описатели использования параметров-переменных). Поэтому имеет смысл выносить их в отдельные вершины; естественно, чтобы они следовали по шампуру за процедурной.
Конечно, принцип визуализации тот же, что для ветви объявлений, но с упрощением — полагаем, что в заголовке определить неатомарный тип невозможно — можно только использовать именованное определение. Поэтому предлагается применять единичные вершины атомарных типов и Полка для объявления величин, типизированных неатомарно.
Вообще-то это вопрос скорее стиля и визуализации, и деклар-моделирования вообще — конкретный прогязык может позволять неатомарную типизацию формальных параметров прямо в заголовке процедуры, и для такого языка данное упрощение станет стилевым ограничением (которое сочинитель мог бы соблюдать и не используя визуализацию).
Понятно, что все эти правила нужно отражать на комплексной абстрактной графит-модели АТ-схем.
Компоновка схем также подчиняется определённым правилам «метра и ритма». Они не влияют на топологию графа, а значит, и на формальность модели, но имеют эмоциональное (эстетическое и эргономическое) значение, помогая человеку воспринимать схему. Введены следующие правила (под содержанием узла И понимается совокупность веток, присоединённых к его выходам):
ось, по которой располагается вход узла И, служит разделителем «правого» содержания этого узла от «левого»; примыкающие края «ритмических областей» содержания располагаются с симметричным отступом от этой оси;
вершина-заголовок узла И (и все нижележащие по входному шампуру, если они есть) выравниваются так, чтобы либо не выступать за края содержания узла, либо выступать симметрично (при этом каждая м.б. несимметрична относительно шампура);
ненагруженными с каждой стороны узла И изображаются по одной ветви с шампурами различной длины; у «левой» ветви (процедур) он длинее, чем у «правой» (данных), что косвенно акцентирует потенциально большую сложность определения в первой;
края узла И могут выступать за крайние оси, подчёркивая возможность расширения состава ветвей как справа, так и слева;
линии узлов И одного ранга видимости располагаются на одном уровне, если это возможно (существенное препятствие — когда на данном уровне и/или выше у некоторых узлов есть вершины-определители ФП, из-за чего суммарные высоты по процедурным шампурам неравны);
вершина-терминал, замыкающая ряд секций, выравнивается относительно крайних осей секций, т.е. выступает одинаково от каждой из них;
точки ввода атомов на схемах не изображаются, но подразумеваются компоновкой; так, процедурная вершина смещается на шампуре вверх, чтобы акцентировать возможность ввода под ней вершин ФП;
содержание ветвей отделяется меньшими промежутками, чем содержание групп ветвей (секций и сторон И-узла, разных И-узлов);
допускается пересечение входной оси узла И, если нужно уплотнить компоновку (обычно лежащего через уровень выше, если не требуется особая плотность); при этом не пересекается край «ритмической области» данных.
Эти правила уже относятся не к языку, а к реализации; скажем, редактор АТ-схем мог бы создавать схемы и их элементы в «жёсткой» компоновке, предоставляя в то же время сочинителю возможность подгонки для оптимизации компоновки на диосцене.
Обсудим соотношение импер- и деклар-частей в комплексной графит-модели. Общие схемы объективно должны строиться сами по себе. Для частных схем, особенно небольших процессов, привлекательной кажется единая структура, абстрактно представляемая следующей ОС-схемой:
Предварительное графит-АТ-определение процесса (Оберон-процедуры) с совмещением моделей частных знаний
Эта же схема может рассматриваться как АТ-определение процедурного типа, существующего в Обероне/КП (впрочем, в последнем он считается устаревающим; учитывая, что КП позиционируется как "живой" диалект Оберона, это можно считать практически значимым; однако есть альтернативные предложения - см. замечание И.Ермакова в этом сообщении).
Заметим, что процедуре нужны графит-определения формальных параметров, когда они имеются. Поэтому схема вариантна в заголовочной части.
В то же время разнесённое изображение импер- и деклар-схем упрощает компоновку модели на диосцене, особенно если схемы сложные. Также м.б. удобнее рассматривать и редактировать автономные схемы.
Глобальная область видимости соответствует узлу И, растущему из заголовка схемы (который определяет имя модуля). Понятно, что модуль выбран за единицу общности АТ-схемы; экспорт, как и в ПК-языке, отражается окончаниями имён по правилам текстового языка.
Более высокий уровень обобщения подразумевает показ всех одновременно загруженных модулей (которые уже связаны только по экспорту/импорту). Для этого можно составить "схему типов среды" из схем модулей с сохранением их заголовков. При автономии визуального редактора от среды использования визуальных моделей такая схема будет лишь "схемой проекта", т.е. совокупности одновременно редактируемых модулей (конечно, это относится не только к деклар-моделям).
Экспорт типов означает, что их определения используются за пределами определяющего модуля. Это стоит отразить - скажем, оформлением использования таких типов как вставок типа в схемы.
АТ-схемы также не делают необходимым указание сущностей в дракон-схемах посредством "полок объявления". В самом деле, имеется привязка объявлений к процедуре по имени в заголовке схемы; при совместном предъявлении читателю этого достаточно.
Возникает вопрос: скажем, в ПК-схеме (на "этажах объявлений" модуля) также перечисляются деклар-сущности - не отказаться ли от этого - модуль ведь также описывается АТ-схемой глобального уровня? Здесь надо руководствоваться принципом "разумной достаточности" - не слишком усложнять, но и не упрощать без нужды. В данном случае ПК-описания модуля выполняют роль DEFINITION-текстов, широко используемых в ТЯП-средах (кроме процедур; их полный интерфейс описывается ДМ-схемами - точнее, ДМ-ветками).
Тогда не поименовать ли все сущности процедур модуля на этажах? А это снова выход за разумную достаточность, установленную текстовым прогязыком. Что есть в непроцедурных секциях ТЯП-оператора MODULE - то и пишем.
Теперь д.б. понятней и требование в тексте импер-элементов (отражающем немаршрутную часть), даже в неформальном, выделять как поля имена сущностей (содержится в определении ДР-диалекта ДА-языка). Ведь в импер-модели мы должны употреблять только сущности, объявленные в деклар-модели. Выделение (хотя бы стилем знака текста в ручной реализации графит-ИСП) зрительно отсылает читателя к этой модели за определением сущности; в автоматизированной графит-ИСП за полем скрывается ссылка, по которой заполняется его значение.
Итак, возможны вариации синтаксиса схем.
Кроме того, визуальные определения сложных структур должны отражать не только «дух» назначения, но и «букву», т.е. быть полны в смысле требований языка. Для этого надо задаться каким-либо стандартом прогязыка.
Если руководствоваться стандартом Оберона-2, то о массиве можно сказать следующее. Во-первых, он не запрещает массивы указателей, в т.ч. многомерные. Интересно, что они получаются явными, тогда как в таком прогязыке, как Ява, неодномерные массивы фактически есть массивы указателей — но неявные, из-за чего многомерность невозможна. Во-вторых, не исключается возможность создать массив типа запись, в числе полей которого снова будет массив, и возможно, опять типа запись и т.д. - т.е. тип массив используется повторно на уровне определения. В-третьих, тип массива м.б. и процедурным (трудно представить себе, для чего это потребуется, но тем не менее).
Наконец (и это относится ко всем сочиняемым типам), тип м.б. определён как самостоятельно (в этом случае он именованный) для приравнивания других типов и/или вставки в более сложное определение, так и для прямого определения (как анонимный). Во втором случае также возможны варианты: анонимный тип прямо определяет некоторый набор величин или часть другого сочиняемого типа (и тогда он входит в его схему непосредственно); эти случаи тоже нужно отразить в визуально-текстовом синтаксисе.
Примем, что на несамостоятельность определения указывает ключевое слово типа в его вершине вместо имени; если определение прикладывается к величинам, то их список, как и для простых типов, следует перед ключевым словом. В любом случае текст вершин простых типов теперь должен содержать только указание подтипа (если оно нужно); список же величин, прямо типизируемых данной схемой, переходит в её заголовочную вершину.
Эти обстоятельства можно отразить в более полной схеме определения:
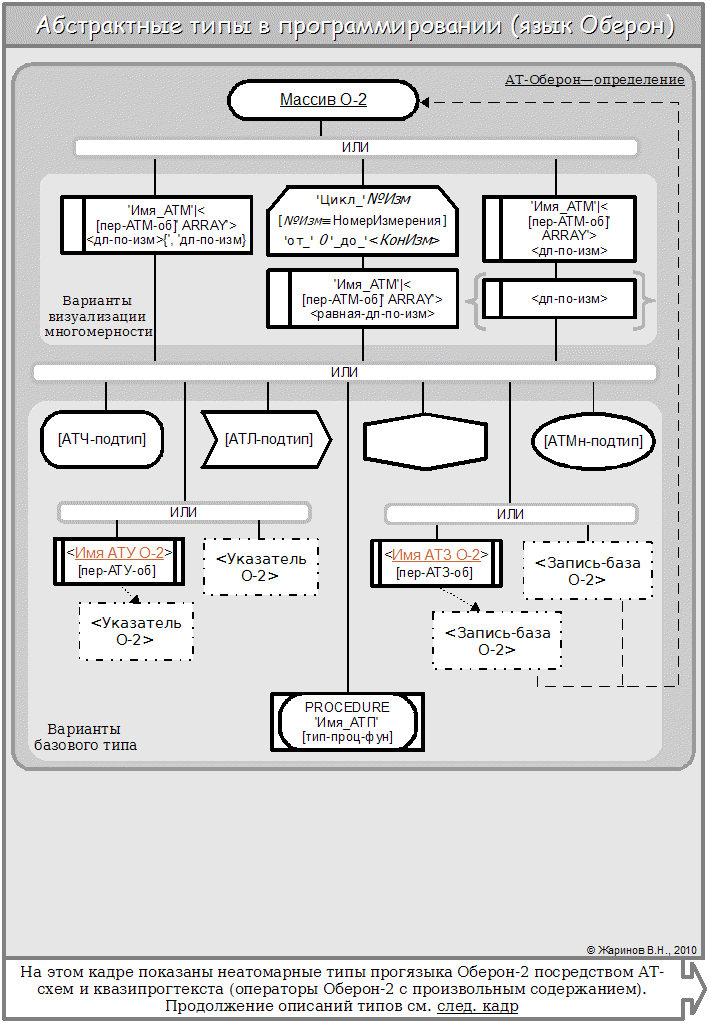
Предварительное АТ-определение Оберон-массива
Аналогично следует поступить для записи. Только здесь надо учесть, что вершины входящих типов представляют поля, которые имеют имена. Переработанное определение см. ниже:
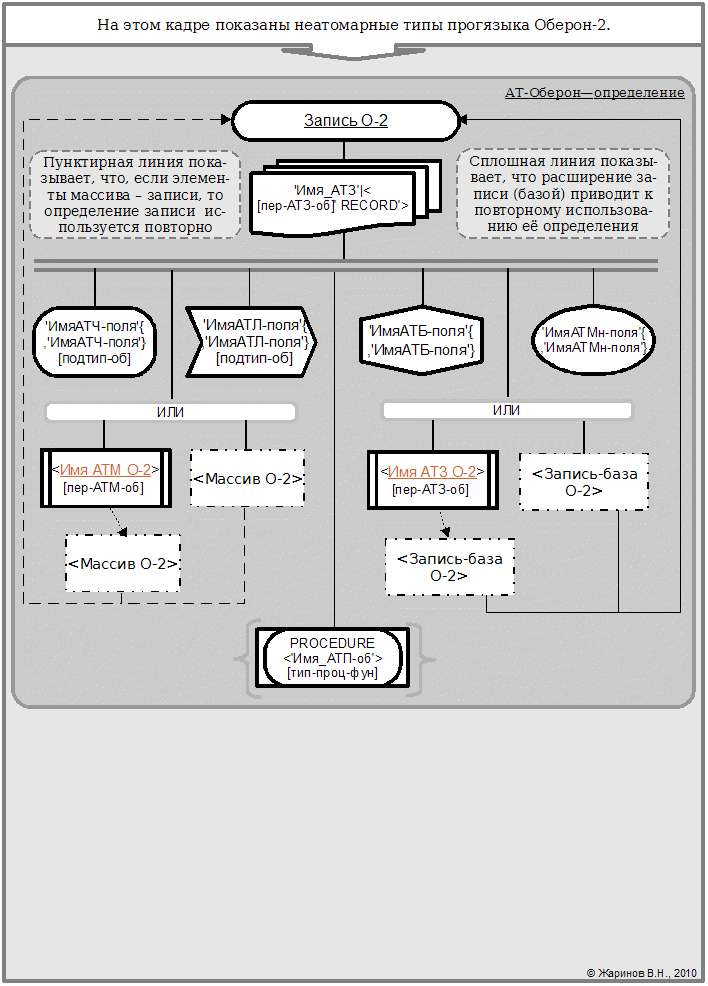
Предварительное АТ-определение Оберон-записи
На схемах также показано употребление АТ-вставок.
А можно ли в абстрактных схемах использовать ОС-узлы И, как в конкретных? Да, можно; для этого надо задавать варианты синтаксиса также, как в текстовой записи — на метаязыке. Мы можем использовать графит-РБНФ; также возможно накладывать на схему графит-ограничители с РБНФ-индексацией.
Конечно, данные визуальные определения сложных структур предварительны и требуют развития. Во многом поэтому в определении АТ-языка пока дан только предварительный алфавит - ещё предстоит выбрать из альтернативных решений.
Видно, что подход отличается от принятого при визуализации в распространённых "визуальных средах". Хотя такая организация выбрана интуитивно, выше указаны её рациональные основания.
Данные положения использованы в примерах визуализации деклар-знаний, а также здесь и здесь в составе совмещённых визуальных моделей.
Выше мы упоминали о модуляризации. Она выходит за рамки частных знаний о деятельности (императивных, декларативных, активных) и относится к обобщённому (объединяющему частные компоненты в целостную систему). Это знание также информатически формализуется; результатом являются различные концепции построения информоделей (прежде всего программ). Как обычно, выберем для рассмотрения в качестве основной какую-то одну, исходя из когнитивной эргономичности и гарантоспособности (проще говоря — чтобы получалось не запутано и работало устойчиво). Ориентируясь на оценки разработчиков гарантоспособных инфорсим, будем рассматривать т.н. компонентное программирование2. Оно основано на группировке сущностей программы в модули — единицы реализации — связанные отношениями управляемой видимости сущностей (импорта/экспорта).
Определим язык описания модульной структуры на графовой основе; при этом постараемся использовать возможности шампур-метода. Язык назван по аналогии с определением, в частности, в стандарте на программные конструктивы.
Начнём с определения модуля. Исходя из стандарта языка, его основное содержание сводится к сущностям следующих родов: процедуры, типы, величины. Они м.б. локальными или видимыми в других модулях за счёт экспорта.
Вершина Модуль визуально структурирует основное содержание Оберон-оператора MODULE следующим образом. Верхний "этаж" содержит определения, относящиеся к модулю в целом - его имя и признаки, зависимые от среды трансляции (Оберон-компилятора)3.
Признак "главности" - для Модулы и модулоподобных реализаций Оберона, где д.б. один главный модуль.
Признак "базовости" - для обязательных модулей Оберон-среды (как-то System, In, Out) - которые помимо всего только импортируются, но не импортируют (по крайней мере явно по тексту). Также экспортируемые ими сущности, как можно понять из Оберон-стандарта, особо не помечаются при имени (т.к. локальные, если они и есть в системном модуле, в программе во внимание не принимаются).
Также вводятся поля служебных данных, определяющих реализацию модуля в символической форме (исходный текст) и предметной (программный код). В принципе это параметры директив сохранения, причём для второго поля директива, естественно, выполняется компилятором (РДП-редактор только генерирует её текст в составе задания на трансляцию; как это задание передаётся компилятору - зависит от его возможностей приёма директив). Содержимое м.б. длинным, поэтому следует его либо переносить, либо прокручивать по горизонтали.
Вообще говоря, логически данная икона соответствует боксу IDEF0-функции, где поля реализации определяют механизм функции; можно даже вынести служебные поля как текст стрелки механизма, но это неудобно для компоновки ПК-схем. Да и сама ПК-схема может рассматриваться как ФМ-схема, уточнённая так, чтобы по ней автоматически генерировать текст ТЯП-оператора модуляризации.
Два следующих этажа определяют частное содержание модуля. Оно включает конкретные сущности всех родов.
Понятно, что здесь сущности только называются. Процедура определяется её дракон-схемой (моделью); тип визуализируется как АТ-схема на языке, который ещё требует окончательного определения (обоснования см. п/п 2.1.5.1). Т.о. имена этих родов суть ссылки на другие схемы.
Величина определяется её именем. Можно задавать и её значение по умолчанию - напр. открывая по щелчку на имени поле ввода.
Также ясно, что сюда не пишутся имена типов и величин, локальных в каждой процедуре - описания локальных в процедуре типов (поименованных в тексте этой иконы) идут опять-таки АТ-схемами, а для их объявления в визуале процедуры м.б. введена вершина Полка.
При наличии ссылок по именам в редакторе вводить полки объявления в визуалы нецелесообразно; это оправдано только для неавтоматизированной визуализации (как «эрзац» ссылок, облегчающий читателю переход к деклар-схемам).
Константы и переменные выступают как виды величин, чтобы не увеличивать число родов; логически это оправдано, а зрительно они м.б. разделены, как показано в иконе - риской, подобно группам пунктов меню в ГИО.
Сокращение числа колонок имеет в первую очередь физический смысл. В самом деле, если допускаем 32-значные имена - то в данном случае ширина вершины Модуль соответствует примерно 100 знакоместам (имена-то эргономично отображать без переноса). Это и то много - значит, либо показываем колонки с горизонтальной прокруткой (не слишком удобно)... либо сокращаем дальше, объединяя, скажем, процедуры и типы.
Можно оставить и одну колонку, помещая в ней разделы (отчёркнутые рисками) в том же порядке, что в MODULE - тогда сочинитель, знакомый с Обероном (а так и д.б. - согласно концепции, изложенной в предисловии переводчика к /Вирт, 2010/), может заполнять её практически "на автомате" и без показа названий разделов.
Колонки дублированы по этажам; на среднем этаже пишутся имена локальных сущностей, а на нижнем - экспортируемых. Каждому роду назначается поле-колонка, совмещённая по ширине на обоих этажах. Выделение границ колонок фоном, а не линиями удобнее для чтения. Колонка м.б. пустой.
По сути, нижний этаж определяет программный интерфейс модуля (в терминах /Свердлов С.З., 2007, с. 161/).
Возможно, средний этаж иконе системного модуля не нужен - раз сочинителя интересует только его интерфейс, но не реализация.
В принципе запись имени на нижнем этаже уже означает его экспорт, т.е. то же, что знак экспорта после имени в исходном тексте. Однако в Обероне экспорт бывает разный, поэтому разумно сохранять этот признак при имени в Оберон-формате, что и показано в РБНФ-тексте иконы. Конечно, РДП-редактор должен допускать ввод этого признака только в именах на нижнем этаже.
Теперь о структуре схем. Она отражает отношение импорта сущностей; в Обероне оно определяется именем (именами) модулей для импорта, из которых в свою очередь импортируются сущности, указанные в качестве экспортируемых.
Естественная форма организации ПК-схем - свободная (сеть модулей). В то же время, т.к. отношения единообразны и однонаправлены (аналогично маршрутам импер-схем), то допускается и силуэтная организация.
Отношения определяются дугами; читателю, знакомому с ПК-алфавитом (в пределах данного описания), выход дуги от нижнего этажа естественно показывает, что экспортируется именно его содержимое, не требуя дополнительных обозначений.
В свободной ПК-схеме втекание дуг определяет список импорта модуля, что в совокупности с текстом вершины Модуль и интерпретацией её графики задаёт содержание оператора MODULE.
В ПК-силуэте полное содержание оператора MODULE визуализируется ПК-веткой.
Вершины-границы ветки имеют графику, общепринятую в логических граф-схемах - здесь все множественные связи реализуются одновременно, т.е. имеет место функция И - а ей соответствует контур прямоугольника с округлением одной стороны.
ПК-петля обозначает переход, в отличие от импер-силуэтов общем случае и множественный - от модуля-экспортёра к ряду модулей-импортёров сущностей, поименованных на нижнем этаже экспортёра, и пустой - если модуль не импортирует другие модули. Это отражено в графике ПК-силуэта - линии петли толстые, а отводы к границам ветки как одиночные, так и множественные через линии-эллипсисы (там, где в тексте иконы-границы имён более одного).
Вообще-то очевидным решением явлется "адресный макроблок", как в дракон-силуэте - в подвале каждому импортёру соответствует отдельная икона Адрес импорта - но это зрительно перегружает схему и логически необязательно, когда переход по петле множественный. Видимо, поэтому же такой подход принял Рэйлвей Каген для силуэтов своего МПК-языка.
Отдельные адреса нужны в том случае, если показывать циклический импорт - тогда имена, образующие цикл, выносим в отдельные иконы-границы в каждой ветке по циклу и индексируем ВЦ в отдельном поле, как и для дракон-схем. В Обероне циклический импорт, как и петлевой (самоимпорт), запрещён (см. /Свердлов С.З., 2007, Прил.1, разд. 11/), поэтому для него это не нужно.
Шапка ПК-ветки отражает, какие модули импортируются данным модулем (т.е. её текст прямо задаёт список импорта). Подвал же ветки показывает, какими модулями импортируется данный модуль.
Разумно ПК-ветку главного модуля ставить крайней левой.
Конечно, правило "чем правее, тем позже" имеет смысл только для единичных связей - здесь же по одному выходу переходим в общем случае на ряд веток, могущих лежать как правее, так и левее инициирующей.
Понятно, что заполнению сочинителем подлежат границы только одного вида - либо в шапке, либо в подвале - текст границ другого вида однозначно определяется этим заполнением (и потому в РДП-редакторе должен генерироваться автоматически).
Можно было бы оставить один вид границ - но сохранение силуэтной структуры и логично, и эргономично - очевидно, сочинителю удобно получать данные обоих видов.
Незаполняемые вручную иконы предлагается показывать блёклой графикой. Так же, а не отсутствием заголовка ветки, считаю целесообразным показывать пустой импорт (предлагаю вводить специальный текст-указание на это, т.к. просто незаполненное поле должно восприниматься как незавершённое оформление отношения импорта).
Заголовок схемы здесь не обозначает вхождение в к.-л. другую структуру; ПК-схема описывает весь текущий состав модулей (доступный для исполнения в Оберон-среде) либо весь состав модулей процесса (при сочинении), и текст её заголовка по сути есть имя проекта процесса (системы процессов). Тем самым текст заголовка по сути называет среду реализации процесса, образуемую модулями.
Визуализация полного состава имеет смысл в рамках визуальной РДП-системы, полностью воплощающей принцип WYSIWYG - "что нарисовано - то и исполнимо" (можно назвать её полногибридной); на сегодня предполагается, что система программирования (трансляции/прогона) отдельная, и в этом случае имеет смысл только ПК-описание отдельного проекта - ведь рисуем в РДП, а делаем исполняемый код, скажем, в ББ.
Т.к. единица компиляции есть модуль, то схема в целом определяет, какие модули д.б. готовы к исполнению для поименованного процесса. Эти данные нужно передать Оберон-среде - напр. в виде директив загрузки модулей (и предварительной компиляции для тех, которые ещё в текущей редакции не были оттранслированы). Конечно, детали зависят от реализации - возможно, потребуется уточнение по результатам ознакомления с конкретной Оберон-средой.
В силу сказанного заголовок присоединяется к ПК-петле без совмещения с вертикалью какой бы то ни было ветки (практически в ПК-заготовке точка ставится между присоединениями двух веток и в дальнейшем такое положение сохраняется - м.б. с ручным выбором, между какими ветками). В свободной схеме заголовок можно присоединять к главному модулю, а если он не выделяется - то в принципе к любому.
Вообще силуэтная форма предпочтительнее и логически, и эргономически. Физически её м.б. сложнее плотно скомпоновать (при существенной разнице высот модулей, определяемой разным объёмом списков сущностей), но это не столь важно.
Совсем приблизить организацию схемы к IDEF0-типу можно было бы, введя управляющие входы. Очевидно, информатически строгий смысл их состоит в изображении отношения вызова процедур управляемого модуля из процедур управляющего. Однако силуэт при этом потерял бы стройность; придётся показывать два разных типа отношений через одну петлю (напр., иконами-границами разной графики); это также и не совсем логично (вызовы-то на самом деле связывают отдельные процедуры из каждого модуля, что мы просто так показать не сможем).
В то же время взаимосвязь процедур в дракон-модели можно визуализировать отдельной схемой такого же рода; тогда модуль заменяется на вставку, представляющую визуал, и показываются отношения вызова из данной процедуры других (в подвале) и данной процедуры из других (в шапке).
По сути это похоже на визуал-концепцию (поэтому назовём такой тип схем дракон-модельными, или ДМ) - но здесь показывается именно структура вызовов. Поэтому в ДМ-схему входят на равных правах все процедуры, включая головную в дракон-модели.
ДМ-схема является вторичной, производной от структуры подстановок визуалов дракон-модели друг в друга (тогда как ПК-схема первичная, сама задаёт структуру модулей)
Естественным будет в ДМ-схеме именовать процедуру уточнённым идентификатором (после имени модуля через точку), как в Обероне. Имя процедуры также является ссылкой на её определение как дракон-схемы; можно делать имя модуля ссылкой, обеспечивая по щелчку на ней переход к этому модулю ПК-схемы.
Как и ПК-схема, ДМ-схема м.б. сводной для общего состава или частной для состава конкретного процесса (проекта).
Фактически сводная схема является обзорной и строится для сведения сочинителя, работающего в РДП-системе с рядом проектов одновременно. Аналогичную роль играют обновляемая страница Node Tree и временная страница Page Structure в DesignIDEF.
Принят следующий принцип образования такой схемы: включаются все модули (или процедуры), причём одинаковые модули входят только один раз независимо от суммарного числа вхождений в процессы; отношения по разным процессам показываются по разным вертикалям, проходящим параллельно через икону модуля (процедуры).
Исходя из этих принципов, определены ПК-язык и ДМ-язык.
Также нам нужно отразить реализацию деятельности конкретным исполнителем. Получааемое описание должно составлять систему с импер- и деклар-описаниями.
Возможный путь намечен в рамках т.н. автоматного программирования. Более точно это метод формализации знаний о деятельности, основанный на явном выделении состояний (ЯВС) предметной области (системы-решателя и её окружения). В отечественной версии ЯВС-методологии определены форматы спецификации исполнителей ЯВС-алгопроцессов (программ). В то же время соображения о спецификации на сегодня предварительные; по необходимости здесь они будут уточнены.
В начало страницы | Оглавление | Главная | Версия для печати
Copyright © Жаринов В.Н.
1Вкратце о языке см. работу: Агафонов В.Н. Спецификация программ: понятийные средства и их организация. – Новосибирск: Наука, Сиб. отд., 1990. – п.10.2.6.
2Напомним, что для нас программирование — это просто информатическое моделирование для формального искусственного исполнителя.
3Они описаны на примерах в /Свердлов С.З., 2007, с. 126-127/.